
Top Open Source Alternatives to Tonic AI for Data Anonymization and Synthetic Data
Top Open Source Alternatives to Tonic AI for Data Anonymization and Synthetic Data
March 31st, 2025

One of the biggest challenges that data engineering teams face is testing their data pipelines without exposing sensitive production data. Most teams either create mock data that doesn't represent their production data well or they copy production data into their lower environments which creates security and privacy concerns. Neither of these approaches is ideal.
This is where combining Neosync with dbt can create a powerful workflow that allows data engineers to build and test their pipelines with anonymized production-like data.
Let's dive into how this works.
Testing data pipelines is complex because you need representative data that matches your production schema and data distributions. If you're working with sensitive data like PII or financial records, you can't just copy that data into your development environment. But if you use mock data, you might miss edge cases that only appear with real-world data patterns.
Here's a common scenario:
Let's see how we can solve this using Neosync and dbt together.
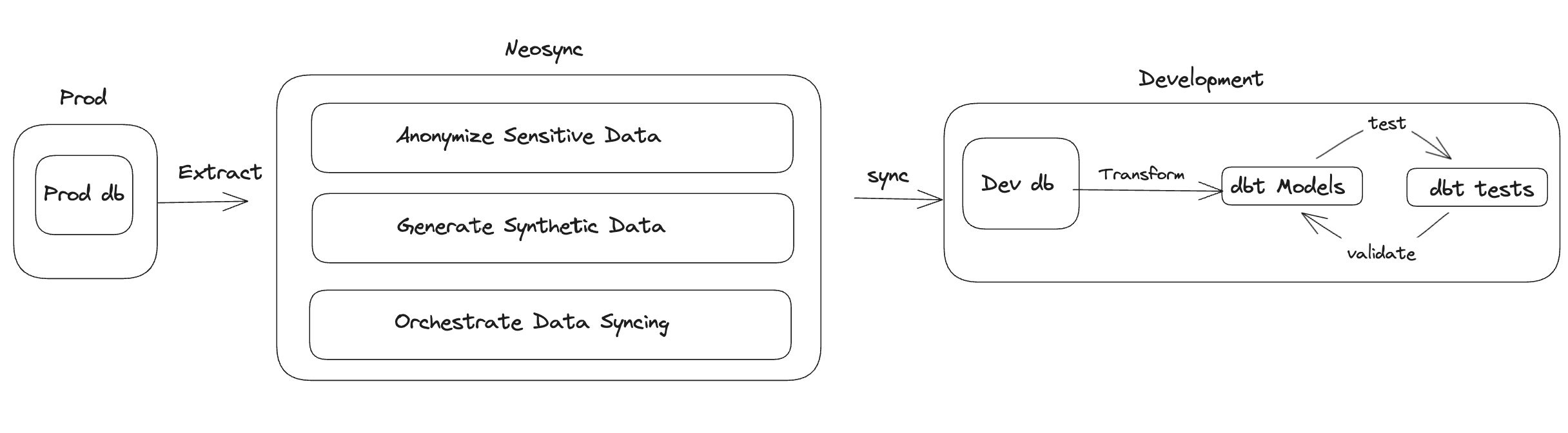
In this architecture:
This gives data engineers a safe way to test their transformations against production-like data without security risks.
Let's walk through how to set this up step by step.
First, create a Neosync job to sync and anonymize your production data. Here's what that might look like:
# Example Neosync job configuration
job:
name: 'prod-to-dev-sync'
source:
connection: 'prod-warehouse'
destination:
connection: 'dev-warehouse'
transformers:
- column: 'email'
type: 'email_anonymize'
- column: 'customer_id'
type: 'generate_uuid'
- column: 'address'
type: 'address_anonymize'Integrate with dbt
Next, update your dbt project to work with the anonymized data. Your profiles.yml might look something like:
dev:
target: dev
outputs:
dev:
type: snowflake
account: your-account
database: DEV_DB # Contains anonymized data
schema: dbt_dev
prod:
target: prod
outputs:
prod:
type: snowflake
account: your-account
database: PROD_DB
schema: dbt_prodBuild Testing Workflow
Now you can create a comprehensive testing workflow:
# 1. Sync anonymized data
neosync jobs trigger prod-to-dev-sync
# 2. Run dbt tests against anonymized data
dbt test --target dev
# 3. If tests pass, deploy to production
dbt run --target prodHere are some key practices we've seen teams implement successfully:
This approach has several benefits:
Combining Neosync and dbt creates a powerful workflow for testing data pipelines with anonymized production data. This approach gives data engineers the confidence that their transformations will work in production while maintaining data privacy and security.
If you're interested in trying this workflow, you can get started with Neosync today. We'd love to hear how you're using it with your dbt workflows!
Top Open Source Alternatives to Tonic AI for Data Anonymization and Synthetic Data
March 31st, 2025

Top 4 Alternatives to Tonic AI for Data Anonymization and Synthetic Data Generation
March 25th, 2025

Nucleus Cloud Corp. 2025