
Top Open Source Alternatives to Tonic AI for Data Anonymization and Synthetic Data
Top Open Source Alternatives to Tonic AI for Data Anonymization and Synthetic Data
March 31st, 2025

As a developer, you need data in order to build, test and debug features. Most of us end up hand-writing mock data and stuffing it into a script that runs when we stand up our local environment. But this only covers a small subset of the use-cases that we need data for and it usually isn't representative of the data that we see in production in structure and messiness. Ideally, we would love to test against production data but there are obvious security and privacy concerns.
So then how do we get high-quality to test and debug our code?
This was the question that started Neosync and the one that we outlined in our Introducing Neosync blog. Over the last year, we've been working with companies of all shapes and sizes to help them anonymize and orchestrate sensitive data from production to lower level environments.
During that time, customers have been asking us to help them generate and move data to other parts of their stack so they can test their streaming infrastructure, messaging queues, data pipelines, batch processes, APIs and more.
And it's become clear that there is an opportunity for Neosync to support more than just databases. We've now reached a point where we believe that it's time to introduce a new type of platform that allows developers to self-serve pretty much any kind of data that they need to build, test and debug their code, applications and infrastructure.
For a while now, our customers at Neosync have been referring to us as a Developer Data Platform. Initially, we didn't think too much of it but recently we've realized that this is a perfect name for this type of platform. So we decided to make it official.
Neosync is a Developer Data Platform or a DDP.
Definition: A Developer Data Platform allows developers to define, generate, orchestrate and self-serve data for databases, APIs, data pipelines, messaging queues, batch processes and more in order to build, test and debug their code and applications in a security and privacy-compliant way.
This definition might seem overwhelming but a DDP really does just three things:
Here's how we think about it architecturally.
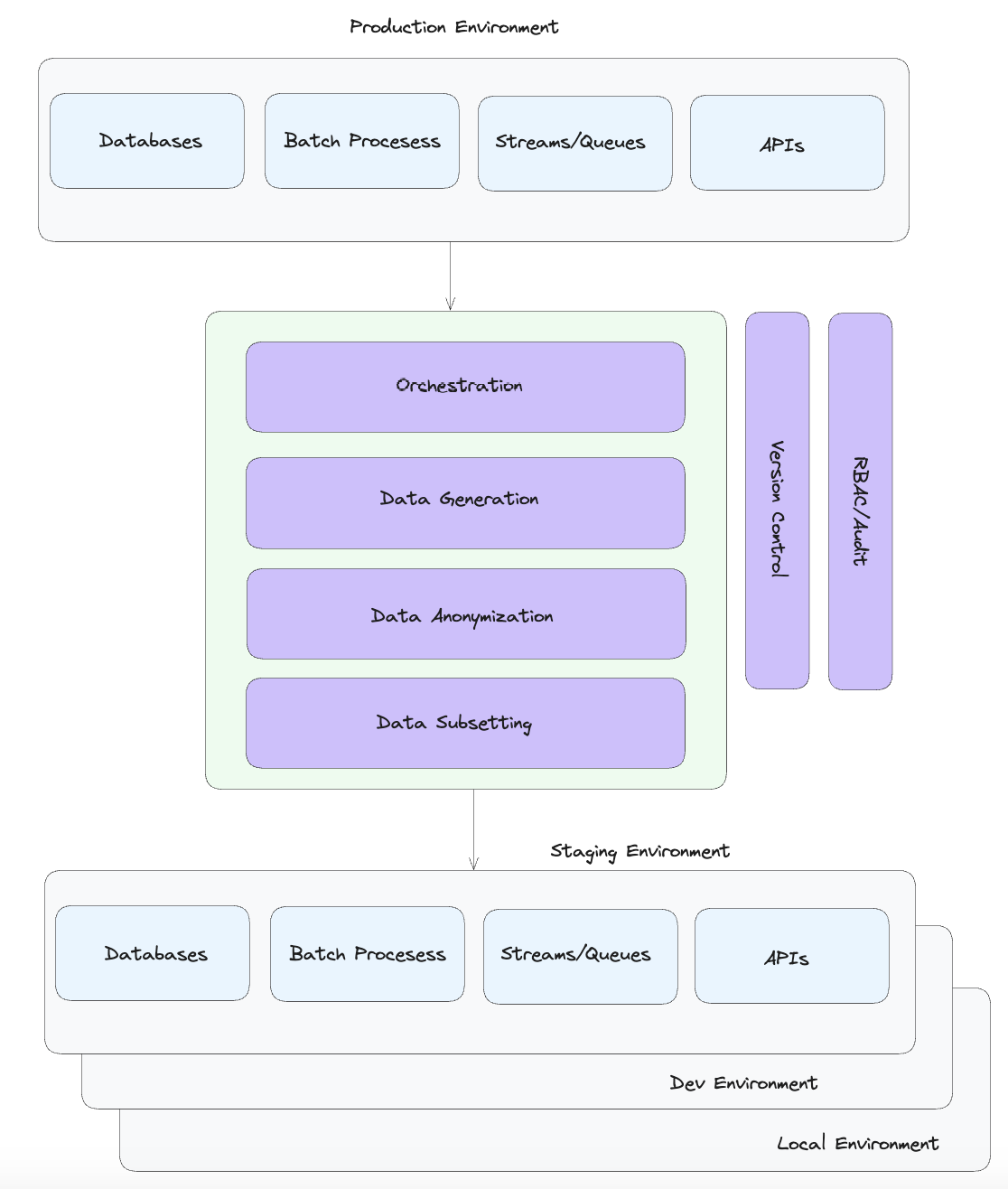
There can be a number of inputs into a DDP such as a database, stream, batch files or even API calls. These datasources feed their data into a DDP where it is anonymized or used as a reference for synthetic data generation. That data is then orchestrated and sync'ed down to databases, object storage or other destinations in lower level environments.
From there, developers can self-serve the data they need based on their use-case from a centralized, version controlled and audited platform. This makes it easier for organizations to track who is using what data and how it's being used. Even though that data is anonymized or synthetically generated it's still important to understand usage patterns and gives developers a way to re-use data sets that others on their team may have already generated.
This is the main question that I expect people to ask and I think it's a fair one. At the end of the day, anytime you're moving data across systems, applications or environments, ETL is the first thing that comes to mind. A DDP definitely does ETL but it also does more that traditional ETL platforms don't do. It also doesn't do things that other ETL platform do.
So I made a table to compare the features of an ETL platform and DDP.
| Feature | ETL Platform | Developer Data Platform (DDP) |
|---|---|---|
| Data Orchestration | Yes | Yes |
| Data Transformation | SQL-based Transformations | Synthetic Data Generation and Data Anonymization |
| Data Generation | No | Yes |
| Data Anonymization | No | Yes |
| Data Subsetting | No | Yes |
| Integration with Databases | Yes | Yes |
| Integration with APIs | Limited | Yes |
| Integration with Messaging Queues | Limited | Yes |
| Integration with Batch Processes | Limited | Yes |
| Self-Serve Data Access | No | Yes |
| Version Control | No | Yes |
| Audit Trails | Yes | Yes |
| Schema Adherence | Often handled | Ensures adherence to existing schemas and type definitions |
| Performance Testing | No | Yes |
| Custom Data Set Creation | No | Yes |
| Privacy Compliance | Not typically addressed | Ensures data is anonymized for privacy compliance |
As you can see, the majority of differences come up in the data sources and the data generation and anonymization. In my mind this is the main difference between ETL platforms and DDPs. DDPs specialize in support different types of inputs and in a core generation/anonymization engine.
There are two questions you can ask yourself to see if you need a DDP:
If you answered yes to either or both of these questions, then you should be using a DDP.
Whether that's user data or other sensitive business data, DDPs will emerge as the go-to platform for data orchestration, generation and anonymization across the stack.
We're at the very beginning of this journey but it's become clear that the world needs a DDP. Developers expect to have a world class developer experience and you can't offer that without world class data. In addition, data security and privacy requirements are only becoming more important for organizations. We believe a DDP is the right solution to protect data and improve developer productivity and efficiency.
Our roadmap is long but we're excited to create this category and bring this platform to market.
Evis & Nick
Top Open Source Alternatives to Tonic AI for Data Anonymization and Synthetic Data
March 31st, 2025

Top 4 Alternatives to Tonic AI for Data Anonymization and Synthetic Data Generation
March 25th, 2025

Nucleus Cloud Corp. 2025