
Top Open Source Alternatives to Tonic AI for Data Anonymization and Synthetic Data
Top Open Source Alternatives to Tonic AI for Data Anonymization and Synthetic Data
March 31st, 2025

Data generation is at the heart of what we do at Neosync so it's no surprise that we're constantly trying to optimize our performance. We recently spent a few days digging into how we do our batching and connection pooling when we connect to a database and were able to further optimize our system and reduce the time it takes to generate data by 50%!.
Let's jump in.
To start, let's look at what we were benchmarking before we optimized our data pipelines across both job types.
For reference, a Data Generation job is one where a user selects a number of records to create for a given table in Postgres or Mysql. Neosync connects to the database, we read the schema and then depending on the Transformers, we start to generate data until we reach the row count that they have given us.
Here are our prelim benchmarks in seconds.
| Rows | 7 Columns | 14 Columns | 21 Columns |
|---|---|---|---|
| 1,000.00 | 1s | 1s | 1s |
| 10,000.00 | 4s | 5s | 6s |
| 100,000.00 | 31s | 43s | 51s |
| 1,000,000.00 | 259s (4min 19s) | 432s (7min 12s) | 471s (7m 51s) |
We benchmarked across two dimensions: row count and number of columns. We ran each combination of row count and number of columns 3 times and then took the average of the three runs and recorded the data above. We also varied the data types in each column across varchar(255), integer, double and text. If we standardized each column as a varchar it likely would have been faster than, say, doubles. But we wanted to mimic data we would generate.
To get a clearer picture, we can graph this data with the row count on the X-axis and the time (number of seconds) on the Y-axis. We can plot a line for each number of columns group. We also use a log scale for the X-axis to more clearly see differences.
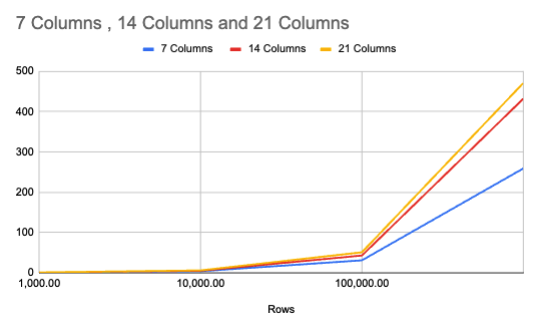
Looking at the graph, a few things stick out.
Up until 10,000 rows, the times are very close to each other regardless of the number of columns. We start to see some separation at 100,000 rows and then at 1,000,000 rows we definitely see separation between the 7 column runs and the 14 and 21 column runs.
Interestingly, we don't see as much separation between the 14 and 21 column runs as we do for the 7 and 14 column runs.
Optimizing code can be really fun but you can also get trapped into hyper-optimizations. We tried really hard to narrow down our optimizations to only the most impactful ones and said early on that we only wanted to implement one or two in this round.
Luckily, we had talked about doing these optimizations for a few weeks so they were top of mind.
One of the first things we built when we started building Neosync was our data insertion module. It basically handled all of the data insertion logic when we insert data into one or multiple destinations.
Now that we're a lot older, wiser and with more gray hair, we wanted to circle back and optimize this module.
Previously, we would effectively create one SQL INSERT statement for each row that we wanted to insert into the database. If you're inserting 1,000,000 records across 20 tables, that's 20M INSERTstatements, that's a lot. And clearly not efficient.
With some work, we were able to introduce batching into this process, where we create a batch of 100 INSERT statements in a buffer and then insert that batch into the database. So we were able to cut down the number of INSERT statements by a factor of 100.
This really helped to speed things up. We also moved away from creating our own INSERT statements in raw SQL to using goqu as a SQL builder. It's fast and flexible and really helped to streamline our data insertion process.
Our first implementation of Neosync didn't optimize how many connections we were opening to the database which caused intermittent connection errors if we were opening too many without closing existing ones.
This happened because we parallelize the generation and syncing progress and each thread will try to open a connection to the database and then once it inserts the data, it closes that connection.
This would occasionally throw an error saying that have reached the connection limit and cause our system to wait until we could close an existing connection and then retry again. This introduced a lot of waiting time until an existing connection closed which ate up a lot of time.
After some work to implement connection limits, we saw a massive drop off in connection errors and much faster data generation times. So now for each database integration, we expose a max connection limit, with the default of 80, to ensure that we don't (or rarely) hit any connection limit errors. By preventing this error, we don't have to wait and retry to open another connection which saves a lot of time.
Once we implemented our optimizations, we saw a pretty big reduction in the time it takes to run our data generation and sync jobs.
Let's take a look.
Here are the new benchmarks for data generation jobs across the same dimensions as before.
| Rows | 7 Columns | 14 Columns | 21 Columns |
|---|---|---|---|
| 1,000.00 | 1s | 1s | 1s |
| 10,000.00 | 2s | 2s | 3s |
| 100,000.00 | 15s | 20s | 26s |
| 1,000,000.00 | 127s (2min 7s) | 183s (3min 3s) | 244s (4m 4s) |
And the graph.
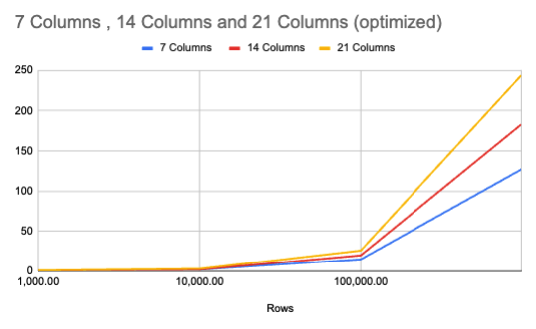
The structure of our graph stayed pretty much the same except the difference in time between the 7 and 14 column is now almost equal to the time between the 14 and 21 column runs for the 1,000,000 rows. We were just able to cut the time in half across all of the measured benchmarks besides the first one which was already at 1 second.
The 21 column, 1,000,000 row job now only takes 4 minutes and 4 seconds instead of 7 minutes and 51 seconds before. That's pretty cool!
We've been making a lot of optimizations to speed up the time it takes for us to generate, transform and sync records across databases. Anytime you can reduce your processing time by 50% you take that as a win. But there are still more things that we can do to optimize our pipelines even further. Particularly around our transformers and how we generate and anonymize data. Those will be coming soon enough and we'll publish another blog post once those improvements are out.
Until next time!
Top Open Source Alternatives to Tonic AI for Data Anonymization and Synthetic Data
March 31st, 2025

Top 4 Alternatives to Tonic AI for Data Anonymization and Synthetic Data Generation
March 25th, 2025